
OUR SERVICES
KloverCloud Data + AI Platform on Kubernetes
Klovercloud offers a comprehensive Data and AI platform built on top of Kubernetes, providing scalable and secure infrastructure for managing, deploying, and optimizing data-driven applications.
Our platform simplifies the complexities of AI workloads by leveraging Kubernetes’ orchestration capabilities, enabling seamless integration, efficient resource management, and robust data pipelines. With Klovercloud, businesses can accelerate AI development, ensure high availability, and maintain agility in their data operations.
KloverCloud Data and AI Platform
Klovercloud ensures the high availability of important kubernetes components like etcd, api-server. Regular backup and restoring assures quick emergency response.
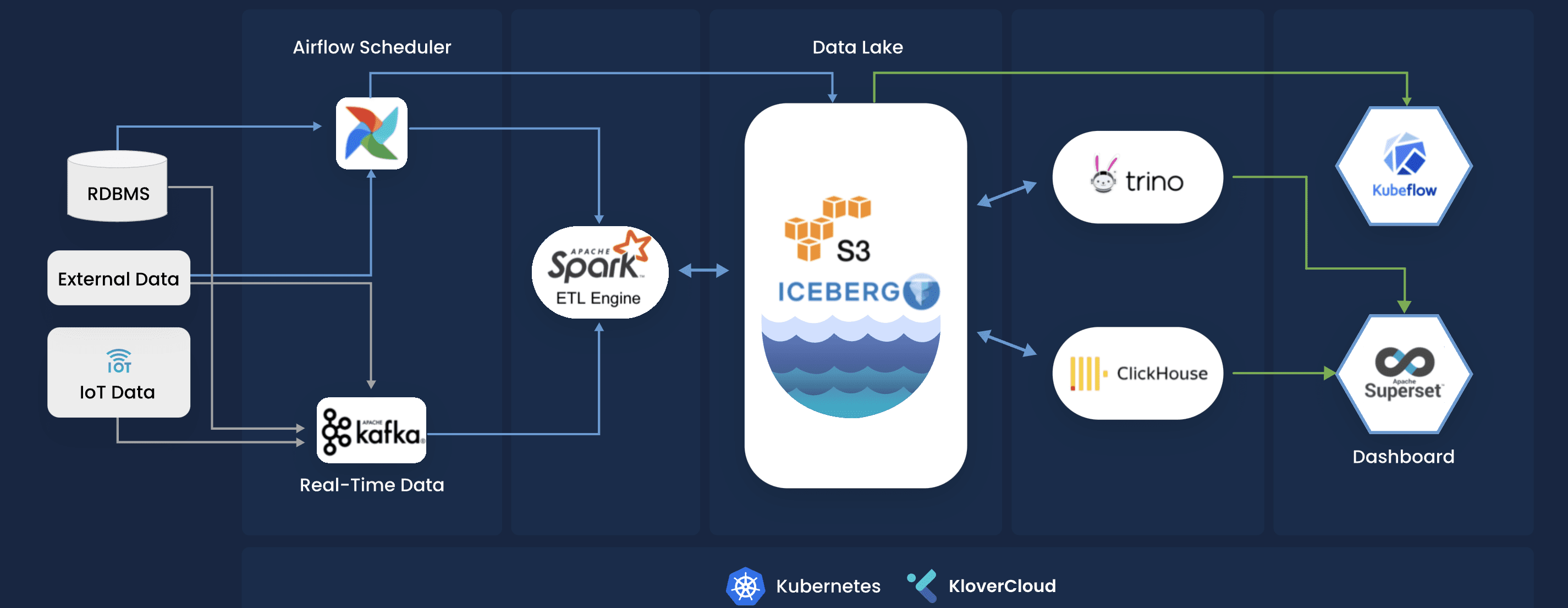
Underneath Technologies of KloverCloud Data + AI Platform
Klovercloud ensures the high availability of important kubernetes components like etcd, api-server. Regular backup and restoring assures quick emergency response.

Kubernetes is the de-facto container orchestrator for running production workloads at any scale. It is used as the main tool to manage resources and distribute workloads of KloverCloud Data + AI Platform.

In a Kubernetes data lake solution, Apache Airflow serves as the backbone for managing and executing data workflows at scale. It integrates seamlessly with Kubernetes to dynamically allocate resources, enabling parallel processing and optimizing performance.

Apache Kafka is a distributed event streaming platform sed by thousands of companies for high performance data pipelines, streaming analytics, data integration, and mission critical applications. It is used as an enterprise event bus in this platform for streaming real time data from different sources to Data Lake

Apache Spark is a distributed engine for large scale data processing, data engineering, data science, and machine learning with implicit data parallelism and fault tolerance. It is used as the ETL Job Processing Engine in this platform.

Object storage technology is a massively scalable storage service. It provides a very high level of durability, with high availability and high performance. It is the largest and most performant storage service for structured and unstructured data and the storage service of choice to build a Data Lake. Different cloud providers provide their own version of Object Storage Service like AWS S3, Google Cloud Storage and Azure Blob Storage.

Hive Metastore (HMS) is a service that stores metadata related to Apache Hive and other services, in a backend RDBMS, such as MySQL or PostgreSQL. When new data is saved to object storage, we register it into Hive Metastore. This declarative phase maps a set of objects in the object store to a table exposed by Hive. Part of registration includes specifying the schema of the table held in the file, with some metadata describing the columns. Using Hive Metastore in this way provides four main benefits related to: Virtualization, Discoverability, Schema Evolution & Performance.

Trino is a fast distributed SQL query engine for big data analytics against any amount of data. With Trino, we can query raw data from Data Lake with ANSI SQL syntax. It works with huge sets of BI tools such as Tableau, Power BI, Superset and many other.

ClickHouse is a super-fast & high performance columnar OLAP database management system for real-time analytics sing SQL. It is sed as the Data Warehouse solution in KloverCloud Data + AI Platform.

Kubeflow is a machine learning platform designed to enable using machine learning pipelines to orchestrate complicated workflows running on Kubernetes. Kubeflow was based on Google’s internal method to deploy TensorFlow models.
Apache Superset is a modern data exploration and visualization platform. Superset is fast, lightweight, intuitive, and loaded with options that make it easy for users of all skill sets to explore and visualize their data, from simple line charts to highly detailed geospatial charts. It is used as the default BI Visualization tool in our platform.
Apache Iceberg is an open table format for huge analytic datasets and rapidly becoming an industry standard for managing data in data lakes. Iceberg introduces new capabilities that enable multiple applications to work together on the same data in a transactionally consistent manner and defines additional information on the state of datasets as they evolve and change over time. The Iceberg table format has similar capabilities and functionality as SQL tables in traditional databases but in a fully open and accessible manner such that multiple engines (Dremio, Spark, etc.) can operate on the same dataset. Iceberg provides many features such as:
- Transactional Consistency between multiple applications where files can be added, removed or modified atomically, with full read isolation and multiple concurrent writes
- Full schema evolution to track changes to a table over time
- Time travel to query historical data and verify changes between updates
- Partition layout and evolution enabling updates to partition schemes as queries and data volumes change without relying on hidden partitions or physical directories
- Rollback to prior versions to quickly correct issues and return tables to a known good state
- Advanced planning and filtering capabilities for high performance on large data volumes